この本との出会い
VROSの運用するにあたって、定期的にやってくるバグ報告。その中で中々再現の出来ないバグに遭遇しました。再現が出来ないというのは、開発者である私から見た想定の範囲外だということです。
大体バグ報告を受けると「言われてみれば、その状況になったら駄目だな」となるはずですが、今回の場合に限っては「まるで意味が分からん」となったわけです。バグ報告をしてくれた方にヒアリングをして行ったら、なんとか再現が出来たのと、解決にまで至りました。
そんな中で、出てきたのがデータベースにおける値の持ち方についての考え方でした。この再現バグとは直結しているわけではなかったのですが、そもそも持ち方をしっかりしていればバグが発生しなかったという内容です。その状況を見た社内の先輩プログラマーに、この本を読んでみてと紹介してもらい、出会ったわけです。
始めに言っておきますが、この本を読んだ上で開発をすればよかったと後悔しています。
どんな本か
タイトルにある通り、SQLアンチパターンが25本分書かれた本です。
章ごとにアンチパターンのテーマがあり、構成は下記のようになっています。
- 目的
- アンチパターンの内容
- アンチパターンの見つけ方
- アンチパターンを用いても良い場合
- 解決策
とてもシンプルです。目次を見て、とても分かりやすいなと思いました。基本的に本は目次を見て、読みたい所から読む派なのですが、気になるアンチパターンから読んで行けるので、この構成は自分にあっているなと思いました。
出てくる、出てくる、胸を打つような、思い当たる節。
思い当たらない節の所もきっと自分の想定範囲外の内容なんだなと思いつつ、恐る恐る見て行きました。
ジェイウォーク(信号無視)
今回のこの本に出会うきっかけのアンチパターンでした。思い切りやっていました、信号無視。
どんな内容かと言うと、データベースの構造内に「カンマ区切りフォーマットのリストを格納する」というものでした。
VROSでやっていたのは「出演者」と「タグ」の二つ。
このリストの格納を行っていたカラムの値も、想定より短くしていたせいというのもあり、上手く番組登録出来ないという事態も発生していました。
今回のこのパターンで一番印象的だったのが、ジェイウォークに引っかかりそうなカラムがもう一つあり、そのカラムについては解決策を講じていたということです。
ジェイウォークの解決策は「交差テーブルを作成する」というものでした。

これが今までのジェイウォークが適用されていた状態です。
ジェイウォークのカラムって書いてあるのが、悍ましいアンチパターンですね。
解決策を講じると、こうなります。
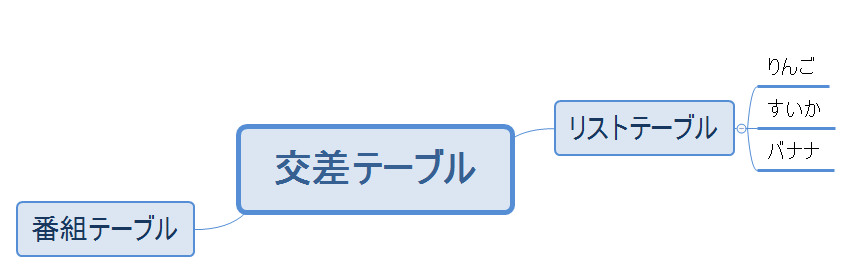
なんかスッキリしたように見える……少なくとも、不確定な感じで延々とカンマ区切りで続くカラムは消えた。
元々持っていたカンマ区切りのカラム情報を入れたテーブルを作って、そのテーブルと番組を繋げる交差テーブルというものを作る。そうすると、いくつ情報が増えてもテーブルのレコードにデータが増えていくだけだし、番組テーブル側で値超過とかも発生しないわけですね。
VROSでこの交差テーブル使っていたのは「良き!」機能でした。番組IDとユーザーIDを紐づけして、良きの交差テーブルを作り、延々とレコードを追加して履歴として残すというものです。このアンチパターンに則ると、きっと良きした人のユーザーをカラムで持って……ってことになったと思います。それこそ、値超過の悪夢に毎日悩まされることになっていました。
では、何故「良き!」は対策をしていて「出演者」と「タグ」については出来なかったのか……それは、単純に想定する時に「良き!」については、かなりの数が来ると思っていたからです。タグや出演者はそこそこ、セーブが効いてくるから、この保存方法にしようと言った感じでした。実際、序盤のほうでは効いていたのですが、やはり運用していくと出演者が滅茶苦茶多い番組もあったというわけです。開発当初の想定範囲外ですね。
そこまで想定出来るエンジニアになって行きたいと思います。
IDリクワイアド(とりあえずID)
カッコ内にある通りです。DBのテーブル全てに「ID」ってカラムを持っていて、それをとりあえず「主キー」としていました。
ただ、これに関してはDANGER!ではなく、WARNING!な段階でした。これを基にしたバグは出ていないからです。
VROSの持つデータベースのテーブルは、通常のサービスと見比べるとまだ少ないように感じます。前述のジェイウォークのように、テーブルを作りたがらないという私の特性もありますが……そのおかげもあって、idとついたカラムだけがあっても、まだ把握しきっている状態です。
というのも、VROSはRubyで動いていまして、SQLは基本的にRubyが発行しているのですが、その際には必ずテーブル名+idのように聞くので、プログラム上だと認識がたやすいからです。
しかし、最近では様々な実装をする上で、SQLを自分で発行して、Rubyに持たせて実行するというパターンも出てきました。そうなると、自分でSQLを作るので、絶対に今後IDリクワイアドを基にしたバグが発生するな……とも思ったので、今回取り上げました。
解決策は割とシンプルで、idというカラムをやめて、テーブル名_idのような形にすること。外部キーとして単体で呼ばれても、何のテーブルの主キーが外部キーとして使われているのかも分かるので、誤解を受けにくくなります。
……誤解を生むのも受けるのも自分自身なのですが。
インデックスショットガン(闇雲インデックス)
インデックス……実はインデックスの機能を全て把握しているかと言われると把握していませんでした。
今回のアンチパターンはインデックスを設定していなかったという点です。
何故設定していなかったのかというと、まだ設定する必要がないかなと思ったわけです。
いずれ来るであろう、パフォーマンスへの問題に差し掛かったら手を出そうと思っていた所だったので……。
幸いなのか、苦悩なのか分かりませんが、まだパフォーマンス関連で問題になったことはありません。考えるくらい利用者を増やさなければいけないという問題点はもちろんありますが……。
なので、今回のパターンについては予習のようなものです。
他のパターンとしては「インデックスを設定しすぎる」「無意味なインデックスを設定する」などの事例がありました。
どのパターンもインデックスのことを理解していない状態で設定すると陥るものだと思いました。
3つのパターンを通して見えたこと
1つ目はカラムの設定、2つ目は主キーの設定、3つ目はインデックスの設定と、よくよく考えたらデータベースの基本という話でした。
VROSという自分が作ったWebサービスに対して、当てはめてみると、基本が出来ていないということに……。
設計をして、製造をして、リリースをしたものに対して、何か改変を加えるというのは滅茶苦茶手間がかかります。更に言えば、仕様が増えれば増えるほど、その影響の範囲はどんどん広がって行くものです。
この本に出会ったのが、まだVROSリリースしてから数ヶ月だったから良かったものの、これが一年後だったらもう、どこに手をつければ良いのか分からない状態だったと思います。
……冒頭にもあった通り「開発の前に見たかった」というのは、ここに繋がってくるわけです。
今後の新規実装については、どんどん活用していきたいと思います!
おまけ:この記事を見てもらって
この本との出会いをくれた先輩に、この記事を見せました。そこで頂いたポイント。
テーブルに入るレコード量を推定出来るようにしよう!
仰るとおりだと思いました!100件入るのと、100万件入るのとでは、大きく異なりますし、後者が適用される場合には、前述にあった通りインデックスを考えなければなりません。
どういうselect文を書く予定か最初に考える
主キーだけでselectする場合にはインデックスがいりませんと。前職でも、そんな話を聞いた覚えがありました。
どんなSQLを書くのかを考えた上で、より取りやすいようになるようデータベースの構築が出来たらなと思います。
explainやりまくろう!
聞いた時はなんだっけ?と思ったんですけど、「実行計画」と言われて思い出しました。そういえば、そんな代物もあったなと。
どういうキーを使って、どういう実行の仕方をしているのかが見えるようになるので、どこがネックになっているのかが見えるというわけですね。
パフォーマンスがおかしい!ってなったら、まずやるべきことの一つだと覚えておくことにしました。